一、哈夫曼树的概念和定义
什么是哈夫曼树?让我们先举一个例子。
判定树:在很多问题的处理过程中,需要进行大量的条件判断,这些判断结构的设计直接影响着程序的执行效率。例如,编制一个程序,将百分制转换成五个等级输出。大家可能认为这个程序很简单,并且很快就可以用下列形式编写出来:


if(score<60) cout<<"Bad"<

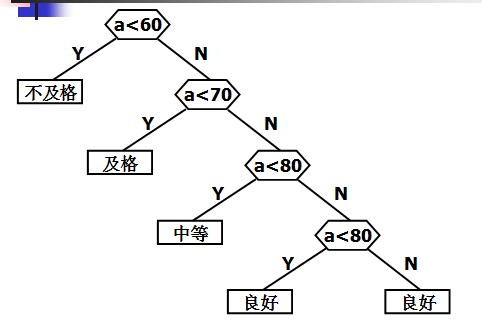
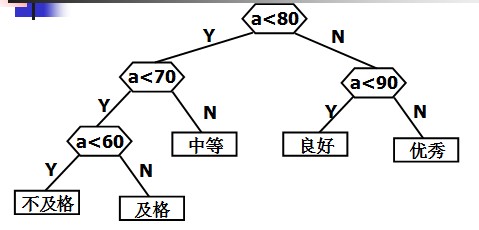
定义哈夫曼树之前先说明几个与哈夫曼树有关的概念:
路径: 树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。
路径长度:路径上的分枝数目称作路径长度。
树的路径长度:从树根到每一个结点的路径长度之和。
结点的带权路径长度:在一棵树中,如果其结点上附带有一个权值,通常把该结点的路径长度与该结点上的权值之积称为该结点的带权路径长度(weighted path length)
什么是权值?( From 百度百科 )
计算机领域中()权值就是定义的路径上面的值。可以这样理解为节点间的距离。通常指字符对应的二进制编码出现的概率。至于树中的权值可以理解为:权值大表明出现概率大!一个结点的权值实际上就是这个结点子树在整个树中所占的比例.abcd四个的权值为7,5,2,4. 这个7,5,2,4是根据实际情况得到的,比如说从一段文本中统计出abcd四个字母出现的次数分别为7,5,2,4. 说a结点的权值为7,意思是说a结点在系统中占有7这个份量.实际上也可以化为百分比来表示,但反而麻烦,实际上是一样的.
树的带权路径长度:如果树中每个叶子上都带有一个权值,则把树中所有叶子的带权路径长度之和称为树的带权路径长度。
设某二叉树有n个带权值的叶子结点,则该二叉树的带权路径长度记为:
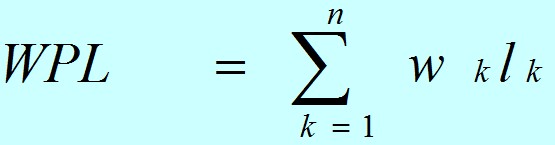
公式中,Wk为第k个叶子结点的权值;Lk为该结点的路径长度。
示例:
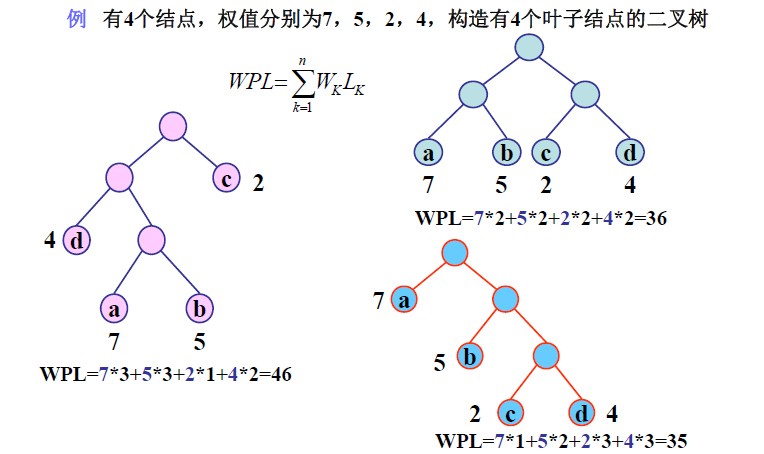
二、哈夫曼树的构造

注意:如果有几棵树根节点权值相等,并且存在一棵树只有一个节点,应该讲这课节点较小的树先出队列。

三、哈夫曼树的在编码中的应用
import java.util.PriorityQueue;public class HuffMan { private static int[] count = { 5, 24, 7, 17, 34, 5, 13 }; private static int N = count.length; private static char[] chars = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' }; private static PriorityQueue priorityQueue = new PriorityQueue (); private static class Node implements Comparable { Character c = null; double w; Node left; Node right; @Override public int compareTo(Object o) { Node n = (Node) o; if (this.w - n.w > 0) return 1; else if (this.w - n.w < 0) { return -1; } else { //如果两个Node的权值相等,将是由其他节点合并而来的节点设置为较小值,先出队列构建霍夫曼树 if (n.c == null) { return 1; } else if (this.c == null) { return -1; } else { return 0; } } } public Node(char c, double w, Node left, Node right) { super(); this.c = c; this.w = w; this.left = left; this.right = right; } public Node(double w, Node left, Node right) { super(); this.w = w; this.left = left; this.right = right; } @Override public String toString() { return "Node [c=" + c + ", w=" + w + "]"; } } public static Node create() { for (int i = 0; i < N; i++) { priorityQueue.add(new Node(chars[i], count[i], null, null)); } while (priorityQueue.size() > 1) { Node left = priorityQueue.poll(); Node right = priorityQueue.poll(); Node newNode = new Node(left.w + right.w, left, right); priorityQueue.add(newNode); } return priorityQueue.poll(); } public static void print(Node node, StringBuilder builder) { if (node.left == null && node.right == null) { System.out.println(node.c + ":" + builder); } else { print(node.left, builder.append('0')); builder.deleteCharAt(builder.length() - 1); print(node.right, builder.append('1')); builder.deleteCharAt(builder.length() - 1); } } public static void main(String[] args) { Node root = create(); print(root, new StringBuilder()); }}